Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
なにかのタイミングで著者のTwitterを見てICLR2022通ったところから見ました。
Excited to share that we have released 170+ pretrained transformer checkpoints of many different shape & sizes as part of our #ICLR2022 paper on "Scaling Transformers Efficiently" 😄.
— Yi Tay (@YiTayML) 2022年2月1日
Checkpoints: https://t.co/cowUl564Tt
Paper: https://t.co/BDG2aBss1I pic.twitter.com/LaHqANOGPU
arxiv自体は去年の9月に初稿が上がっていた模様。
ざっくり内容としては、OpenAIのScaling Laws for Neural Language Modelsを念頭に、
「とりあえずScale upすりゃええやろ、は本当かいな?」といったもの。
OpenAIの論文ではValidation Loss(確かPretrainingのだったのでupstreamにあたる)でしか議論されていませんでしたが、それを(downstream taskの)SuperGLUEのAccuracyで検証している。
モデルはGoogleなのでT5。
T5モデルのどこのパラメータを変えるかで接頭辞がついている。
- DM: model dimension
- FF: FFN hidden size
- NH: number of heads
- NL: number of layers

この図では、どのパラメータ(論文中ではつまみとも)を変えるかで性能の変わり具合が異なることを示している。
例えば一番右のNLは大きく変化するが右から2番目のNHはあまり変化がない。
ここでは、NL(layerなのでtransformerの図のdepth方向)をscaleした方がFF(width)をscaleするより効率が良いと報告している。
なので、同じパラメータ数という観点ではDeepNarrow(transformer層の数が多く(深く)、FFNの数を減らす(細く))するのが良いとしている。
もちろん無限に増やせば良いというわけではなく、層の数は32-36で収束する。
ちなみに、このDeepNarrowの考え方を採用したのがCharformerとのこと。
(また読むべきものが増える…^^;)
[2106.12672] Charformer: Fast Character Transformers via Gradient-based Subword Tokenization
こちらはオージス総研さんのページで実装と概要が述べられている。
はじめての自然言語処理 ByT5 と Charformer の検証 | オブジェクトの広場
DeepNarrowを実践した比較がTable 4になる。
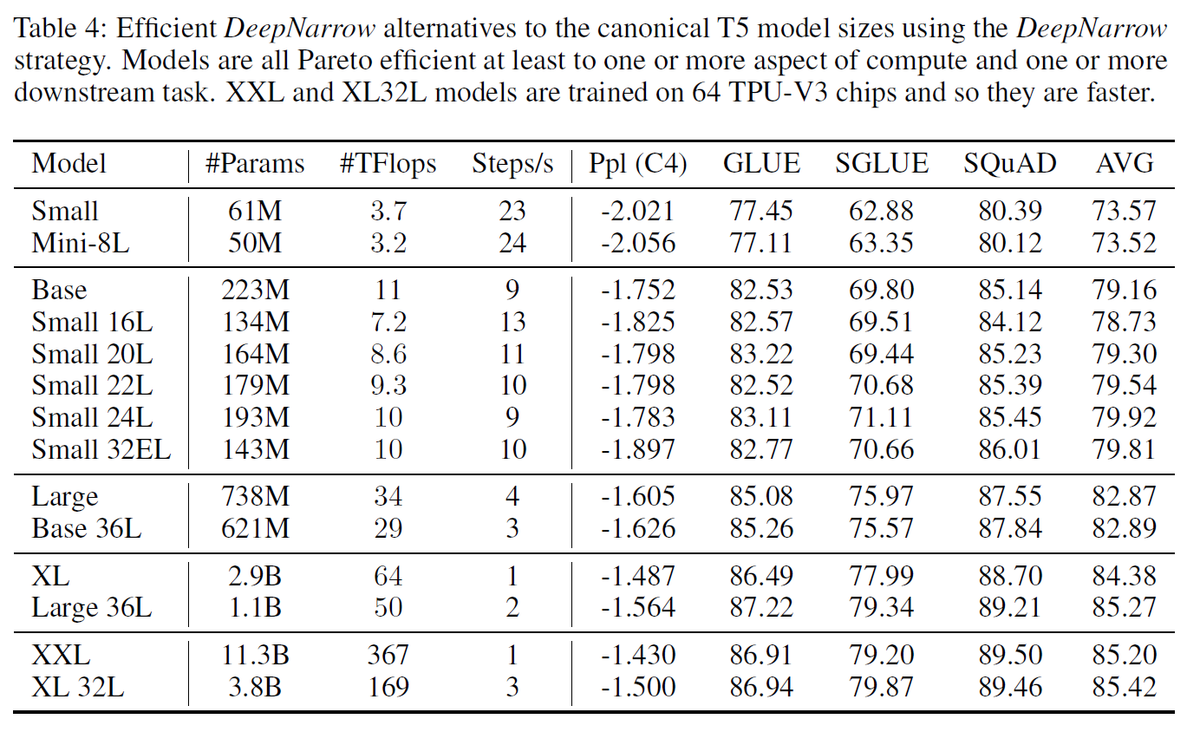
モデルのサイズを1段階小さくしても、layer数を増やすことでパラメータ数やTFlopsを少し小さくしながら同等またはそれ以上の精度を示している。
ただ、大規模モデルでは分散学習させることが多くなるが、深く細くすると並列化に限界が生じてしまうが、この点については考慮しない。
また層を深くすると勾配消失の問題が出てくるが、本論文の実験下では起きなかったとのこと。
Vision Transformer(ViT) や他のNLPタスクでもDeepNarrowの法則は成り立っている(Table 5-7)。
そのため、DeepNarrowは効率的に精度を高められる手法と言えそうだ。